I spent months on the other side of the model — evaluating and training LLM outputs, scoring which answers were "good," teaching the thing what humans want to see.
That experience ruined generic prompting advice for me forever. Because once you've sat in the rater's seat, you understand something most prompt guides never tell you:
The model's default answer isn't its best answer. It's the answer most likely to get a thumbs-up from a tired human reviewer.
Everything else about prompting flows from that one fact. Let me explain what I mean, and then give you the four laws I actually use.
Why your outputs feel so… mid
Here's what training looks like under the hood. Thousands of human raters look at model responses and reward the ones that seem helpful, safe, and complete. Do that at scale and the model learns a specific personality: agreeable, hedge-y, structured, and relentlessly average.
That's not a bug. It's the equilibrium. The model is optimized to produce the response that looks good to someone skimming quickly — not the response that's actually sharp, specific, or correct.
So when you type a lazy prompt and get a lazy answer, the model isn't failing. It's giving you exactly what it was rewarded to give: the safe median of the internet. Your entire job as a prompter is to drag it out of that median.
These are the four laws I use to do it.
Law 1: It wants to agree with you. Don't let it.
Models are trained on human feedback, and humans rate agreeable answers higher than ones that tell them they're wrong. The result is sycophancy baked straight into the weights.
This is why "Is my plan good?" is a trap. The model is biased toward yes before it's read a word.
Flip it. Instead of "Is this a good idea?" ask "You're a skeptical investor who wants to pass on this. What are the three strongest reasons to say no?"
Same model, same topic — completely different answer, because you've removed the incentive to flatter you. Adversarial framing beats approval-seeking framing every single time.
Law 2: By default, it gives you the average. Name who you want instead.
Ask for "marketing copy" and you get the statistical center of all marketing copy ever written — which is to say, slop.
The model contains a thousand voices. If you don't pick one, it blends them into mush. So pick one. "Write this the way a contrarian founder who hates buzzwords would explain it to a smart 15-year-old."
You're not adding a fun persona for flavor. You're collapsing the distribution onto a specific, sharper region of what the model knows. Specificity isn't politeness — it's targeting.
Law 3: It thinks in the tokens it writes. There's no hidden brain.
This one is pure mechanics, and it's the most expensive mistake I see.
The model has no private scratchpad. Whatever "thinking" happens, happens in the text it generates. So if you demand the final answer in the first sentence, it has to commit before it has reasoned — and then it spends the rest of the response rationalizing a guess.
Force the order. "Reason through this step by step, then give your conclusion last."
The reason chain-of-thought works isn't mysticism. You're literally giving the computation somewhere to happen before it locks in.
Law 4: It fabricates exactly the things nobody could fact-check.
Here's a dirty secret from the rater's seat: a human reviewer skimming an answer cannot quickly verify a citation, a statistic, or an API signature. So confidently-wrong specifics slip through training and get reinforced.
That's why models hallucinate the most precise-looking details — the fake DOI, the plausible-but-nonexistent function, the suspiciously round number. Those are the failure modes that survived because they were hard to catch.
So constrain them out. "Only use facts from the text I pasted. If you're unsure, say 'I don't know' — do not guess." Treating the model as confidently unreliable on specifics isn't pessimism. It's accurate.
The cheatsheet, now that you know why it works
Once you internalize those four laws, the standard "anatomy of a prompt" stops being a checklist you memorize and becomes obvious. Each part exists to fight the median.
- Role picks a voice (Law 2).
- Context is the stuff a brilliant stranger with amnesia couldn't possibly guess.
- Examples show instead of tell, because the model pattern-matches harder than it follows instructions.
- Constraints kill the generic defaults — and negative constraints ("no preamble, no hedging") punch above their weight.
- Reasoning buys it room to think (Law 3).
- Output format is where production reliability lives if you're building anything real.
In order:
Role → Task → Context → Examples → Constraints → Reasoning → Output Format
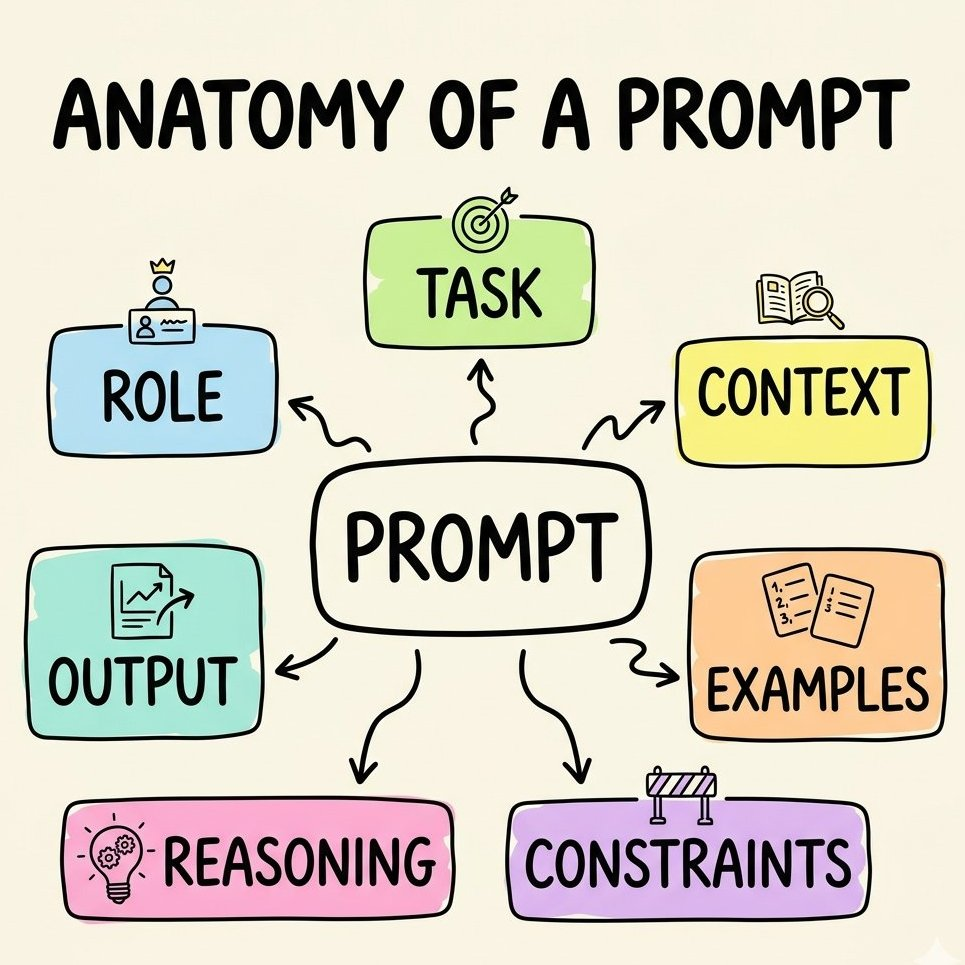
When an answer disappoints, don't rewrite the whole prompt in frustration. Walk the list, find the one part you left out, and change only that. Prompting is debugging, not gambling.
The one move that compounds
Last thing — the highest-leverage trick I know, and almost nobody does it.
When you get a bad output, paste your prompt and the bad answer back in and ask: "Why did this prompt produce this result, and rewrite it to fix it."
The model knows its own failure modes better than you do. Let it engineer the prompt against itself.