I built the same agent in four different agentic AI frameworks. They gave me four different rankings of the same five articles. I stared at the output for twenty minutes trying to figure out why.
This isn't another "what is an AI agent" explainer. I'll assume you already know an agent is an LLM that can call tools and decide what to do next. What I want to talk about is what happens when you build the same thing four times, in LangGraph, CrewAI, Microsoft AutoGen, and the OpenAI Agents SDK, and then read the four outputs side by side.
Here's the thesis. The shape of an agentic framework leaks into the shape of its output. Same model, same prompt, same input data, four frameworks, four different rankings. Picking a framework is picking a failure mode, not a feature set.
I expected to find a winner. I found something more useful: a way to choose between them based on what goes wrong, not what looks pretty in the README.
I went into this expecting one of them to obviously win. By the end I couldn't decide which one I'd ship, and that uncertainty turned out to be the most useful thing I learned. A framework you can defend is more valuable than a framework that wins on paper.
If you want the foundational reference for any of this, Lilian Weng's post on autonomous agents is still where most of the vocabulary the rest of us use comes from.
The Test Agent and the Fairness Rules
The agent's job is deliberately small. You give it a topic, say "Agentic AI frameworks", and it searches the web for recent articles using Tavily, picks the top five results, summarizes each one in two to four sentences, rates each from one to five for usefulness to a senior engineer, and writes a markdown digest to disk. That's it.
This looks boring. That is the point. Most agentic AI demos build trip planners or roleplay chats, and you finish reading them without learning anything you can use on Monday. A boring agent, one that just searches, summarizes, ranks, and saves, strips the magic away. You can actually see what each framework is doing instead of being dazzled by what the LLM happens to say. If a framework can't make the boring case feel natural, it'll never survive the interesting one.
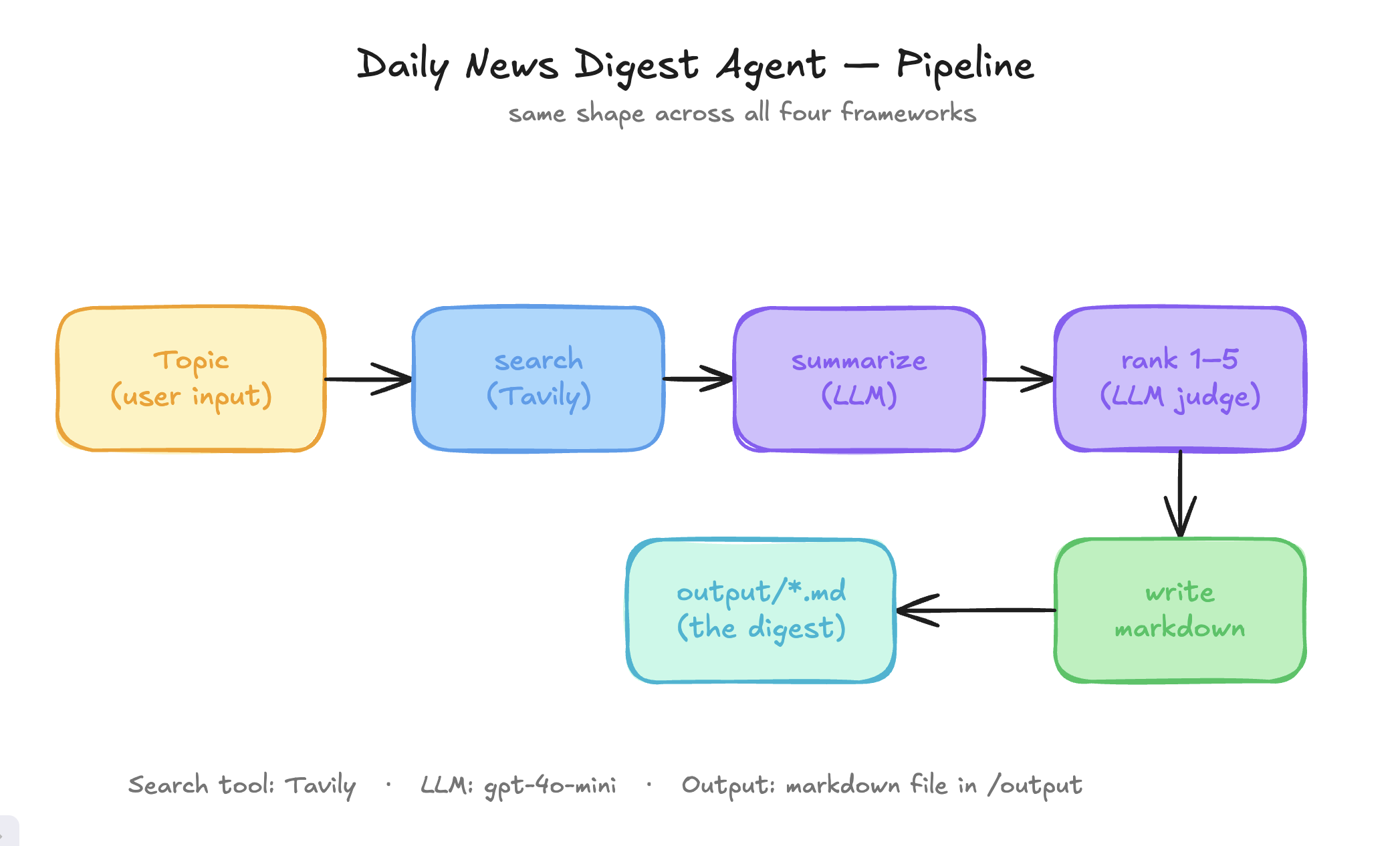
To keep the comparison honest, I locked four rules across all four builds. I used OpenAI gpt-4o-mini everywhere. Cheap, capable, fair. I used Tavily for search, wrapped in each framework's native tool format. I kept the prompts in sync via a shared/prompts.md file so the LLM saw identical instructions in every build. And I defined the output shape in a shared/SPEC.md file so the four output/*.md files would be diff-able.
But, and this matters, I deliberately let each framework be itself. LangGraph got to be a state machine. CrewAI got to be roles. AutoGen got to be a chat. The OpenAI SDK got to be one minimal agent. Forcing them into the same code shape would have hidden the very thing I was trying to learn.
I almost wrote a shared base class so all four agents would call the LLM the same way. Same tool wrapper, same retry logic, same output schema. Then I caught myself. That kind of "fairness" would have hidden the very thing I was trying to learn. I let each framework be itself.
If you want more on when agents are the right tool and when they aren't, Anthropic's "Building Effective Agents" is the best one-pager I've read on the question.
The Four Builds
LangGraph, the state machine
LangGraph treats your agent like a state machine and forces you to admit it. You declare a State (a typed dict), Nodes (functions that read state and return updates), and Edges (which node runs after which). Every step is visible. There is no magic.
Here is the entire pipeline in eleven lines.
def build_graph():
graph = StateGraph(DigestState)
graph.add_node("search", search_node)
graph.add_node("summarize", summarize_node)
graph.add_node("rank", rank_node)
graph.add_node("write", write_node)
graph.add_edge(START, "search")
graph.add_edge("search", "summarize")
graph.add_edge("summarize", "rank")
graph.add_edge("rank", "write")
graph.add_edge("write", END)
return graph.compile()That code matches the whiteboard drawing exactly. Start, search, summarize, rank, write, end. The day a junior engineer joins your team and asks "where does this loop?", you'll be glad it's there.
A stateful graph is just an agent that remembers which step it's on. That's the whole concept. You can draw it on a napkin.
What I like about LangGraph is that it's the most complete of the four. You can add nodes, conditional edges, retries, and human-in-the-loop without leaving the framework. The Tavily tool is built in via LangChain, so you don't even write a wrapper. What I don't like is the ceremony. The state type, the nodes, the edges, it's a lot of boilerplate for an agent that could fit in twenty lines elsewhere. You pay for the explicitness up front.
Docs are at the LangGraph tutorials.
CrewAI, the team of specialists
CrewAI has the simplest mental model to describe to a non-engineer. Your agents are coworkers. Each one has a role, a goal, and a backstory. You hand each of them a task. The framework manages the handoff.
researcher = Agent(
role="News Researcher",
goal="Find the most relevant recent articles on the topic.",
backstory="You gather recent news for a senior software engineer...",
tools=[search_tool],
)That's it. Three fields and a tool. You add a manager agent or a hierarchical process by changing one line. Process.sequential becomes Process.hierarchical and CrewAI invents a manager that delegates. Almost nothing else changes. The whole crew is built from these tiny pieces.
A sequential process is just agents taking turns. The first one's output becomes the next one's input. There is no real magic, just a for loop with extra prose.
What I like about CrewAI is that it's the fastest to write. Adding a fourth agent like a legal reviewer takes about two minutes. You write a new role, goal, and backstory, and you append it to the crew. The mental model maps to how non-engineers already think about teams. What I don't like is that the prose-heavy backstories are also where bugs hide. When something goes wrong, you end up debugging by editing English instead of reading code. For small teams this feels great. For large ones you'll want more structure.
Docs are at CrewAI Crews.
Microsoft AutoGen, the conversation
AutoGen v0.4 thinks of agents as chat participants. You wire up two or three of them, give one a tool, give another the editorial voice, and let them converse until a termination condition fires.
team = RoundRobinGroupChat(
participants=[researcher, editor],
termination_condition=(
TextMentionTermination("DIGEST_COMPLETE")
| MaxMessageTermination(8)
),
)
result = await team.run_stream(task=topic)The MaxMessageTermination(8) is the safety net. Without it, two agents will happily chat forever and your wallet will notice. The | is not a typo either. Termination conditions compose with bitwise operators.
A termination condition is the rule that decides when the agents shut up. Without one, they don't.
What I like about AutoGen is that it's the most natural fit for patterns where agents need to argue and converge. Negotiations, code reviews, debates. The streaming output feels alive. What I don't like is that v0.4 is async-first and the API surface is still moving. If you've used the older pyautogen, the migration is real. The conversational style also tends to produce the shortest outputs of the four. Agents skim each other's messages instead of digesting them.
Docs are at the AutoGen v0.4 migration guide.
OpenAI Agents SDK, the minimalist
If the other three frameworks say "draw me a graph", "write me a job description", and "let them talk", this SDK just says "give me a function and an instruction."
You do have to write your own tools. There's no built-in Tavily wrapper like LangChain has. But the @function_tool decorator does almost all the schema work for you.
@function_tool
def web_search(query: str, max_results: int = 5) -> str:
"""Search the web and return a numbered list of articles."""
return tavily.search(query=query, max_results=max_results)
agent = Agent(
name="NewsDigestAgent",
instructions=INSTRUCTIONS,
model="gpt-4o-mini",
tools=[web_search],
)
result = await Runner.run(agent, input=f"Build a digest about: {topic}")Three lines define the agent. One line runs it. The LLM handles the loop: calling the tool, reasoning over the results, producing the final answer. No graph. No team. No backstory.
A function tool is just a regular Python function the LLM is allowed to call. The decorator reads the type hints and docstring to build the schema the model sees.
What I like about this SDK is that it's the shortest code by far. Under a hundred lines for a real agent. If you already use the OpenAI API, the mental model is identical plus a loop. The minimalism is the feature. What I don't like is that it gives you the least guidance on multi-agent patterns. No built-in tools either, so you wire your own integrations from scratch. If you want a manager agent delegating to specialists, you'll find yourself reinventing what CrewAI gives you for free.
Docs are at the OpenAI Agents SDK site.
The Surprise Nobody Warned Me About
I ran all four agents on the same topic, "Agentic AI frameworks", at the same minute. Same Tavily search. Same five articles in. Here is how each framework rated them, one through five.
| Article | LangGraph | CrewAI | AutoGen | OpenAI SDK |
|---|---|---|---|---|
| Moxo, comparison guide | 5 | 5 | 4 | 4 |
| Akka, 2026 enterprise guide | 4 | 4 | 5 | 5 |
| Hugging Face, intro to frameworks | 4 | 2 | 3 | 4 |
| YouTube, "Best Framework" video | 2 | 3 | 1 | 3 |
| Kyndryl, marketing page | 2 | 1 | 2 | 2 |

Look at the Hugging Face row. Same article, same model, a two-point spread. Two frameworks crowned Moxo the winner. Two crowned Akka. Same input. Same LLM. Different verdicts.
That's the moment of the twenty-minute stare.
Here's my best hypothesis for why. In the LangGraph version, I summarize each article in a separate LLM call, with the article's full content in the prompt. In the other three, the editor agent sees all five summaries (with short excerpts) in one single call. More context per article means more nuance, which means more spread in the ratings.
Put it another way. The architectural choice between calling the LLM once per article and calling it once for all of them is one line of code. That one line surfaced as a user-visible difference in judgment. The framework's shape leaked into the output.
This is the same pattern Discord wrote about when they migrated from Cassandra to ScyllaDB. A small architectural change at the storage layer showed up as a giant user-visible improvement at the chat layer. Architecture is not invisible. It compounds upward.
My first thought when I read the four output files was, "I must have a bug." My second thought was, "I have four bugs, one per framework." My third, twenty minutes in, was, "no, it's not a bug. The frameworks just see the world differently." That's when I stopped trying to fix it and started writing this article.
Some honest caveats. This is one run, one topic, one model. I'm not publishing a paper, I'm publishing a finding. If you re-run the repo with a different topic, you might see a different spread. But you will see a spread. That's the point.
If you want to feel like you're in good company being uncertain about all of this, Simon Willison's notes on agents are a good place to sit with it.
The Verdict, and a Decision Framework You Can Use
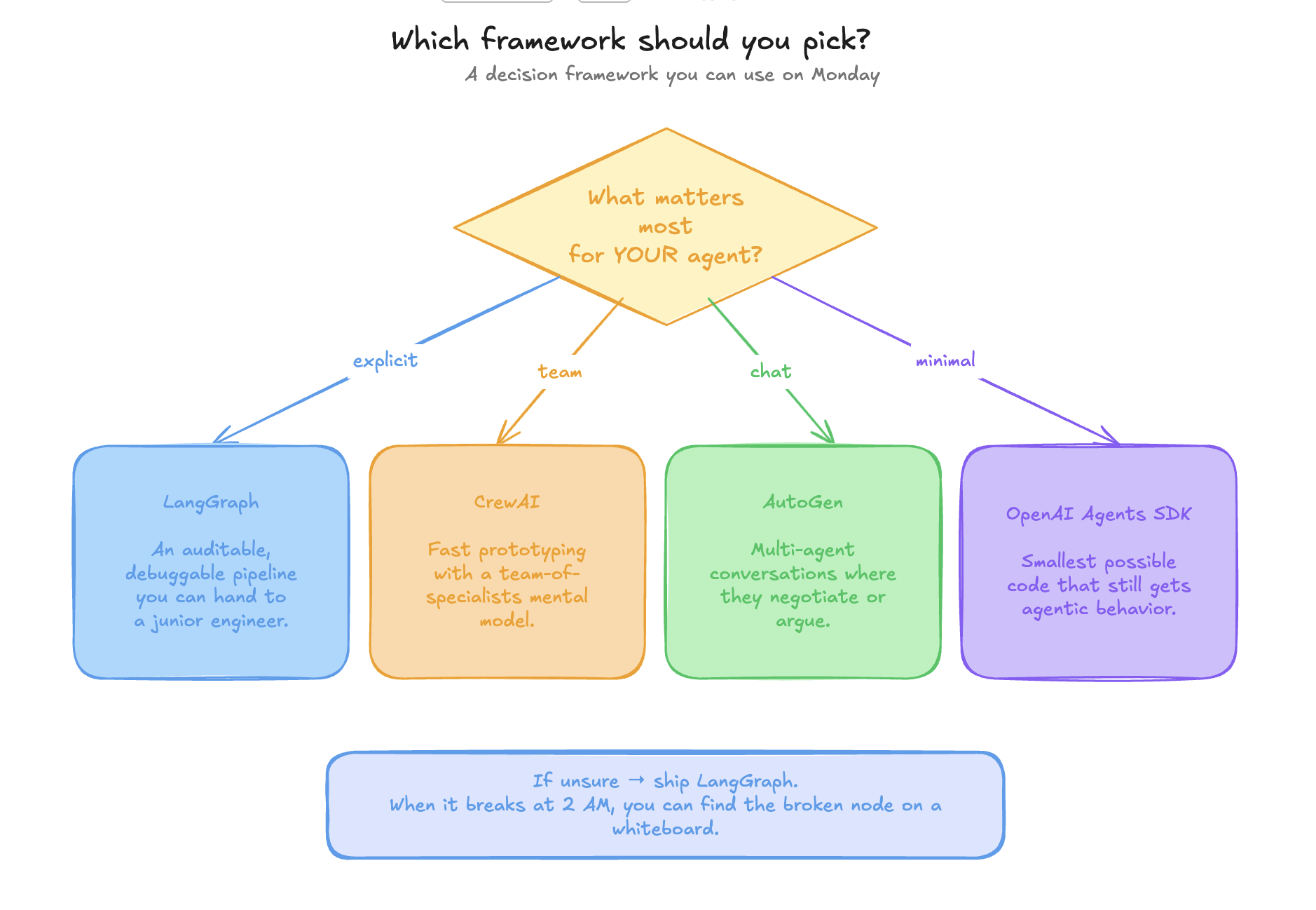
If your reaction right now is "great, but which one do I actually pick?", here is the table I keep on my desk.
| If you need… | Pick |
|---|---|
| An auditable, debuggable pipeline you can hand to a junior | LangGraph |
| Fast prototyping with a "team of specialists" mental model | CrewAI |
| Multi-agent conversations where they negotiate or argue | AutoGen |
| The smallest possible code that still gets agentic behavior | OpenAI Agents SDK |
And the strong opinion.
If I had to ship one to production tomorrow, I'd ship LangGraph. Not because it's the prettiest, but because when it breaks at 2 AM, I can find the broken node on a whiteboard. The same explicitness that feels like ceremony at the start is the thing that lets you sleep at night.
What I'd do differently next time. I'd instrument tokens and latency from day one (I had to estimate after the fact). I'd add a conditional retry edge to the LangGraph version for when search returns nothing. And I'd try CrewAI's hierarchical process. I've heard it changes the feel completely.
If you'd ship a different framework, tell me which one, and why. Especially if you've shipped one to production. The receipts are in the repo. The verdict is yours. I want the war stories.
The repo is at github.com/junaiddshaukat/four-agents-one-job. Clone it, add your two API keys, and run all four with one shell loop. The four output/*.md files are the receipts, for me and for you.
Total reading time, about ten minutes. Total code, repo-wide, under a thousand lines. Total cost to run all four agents back to back, under three cents.